
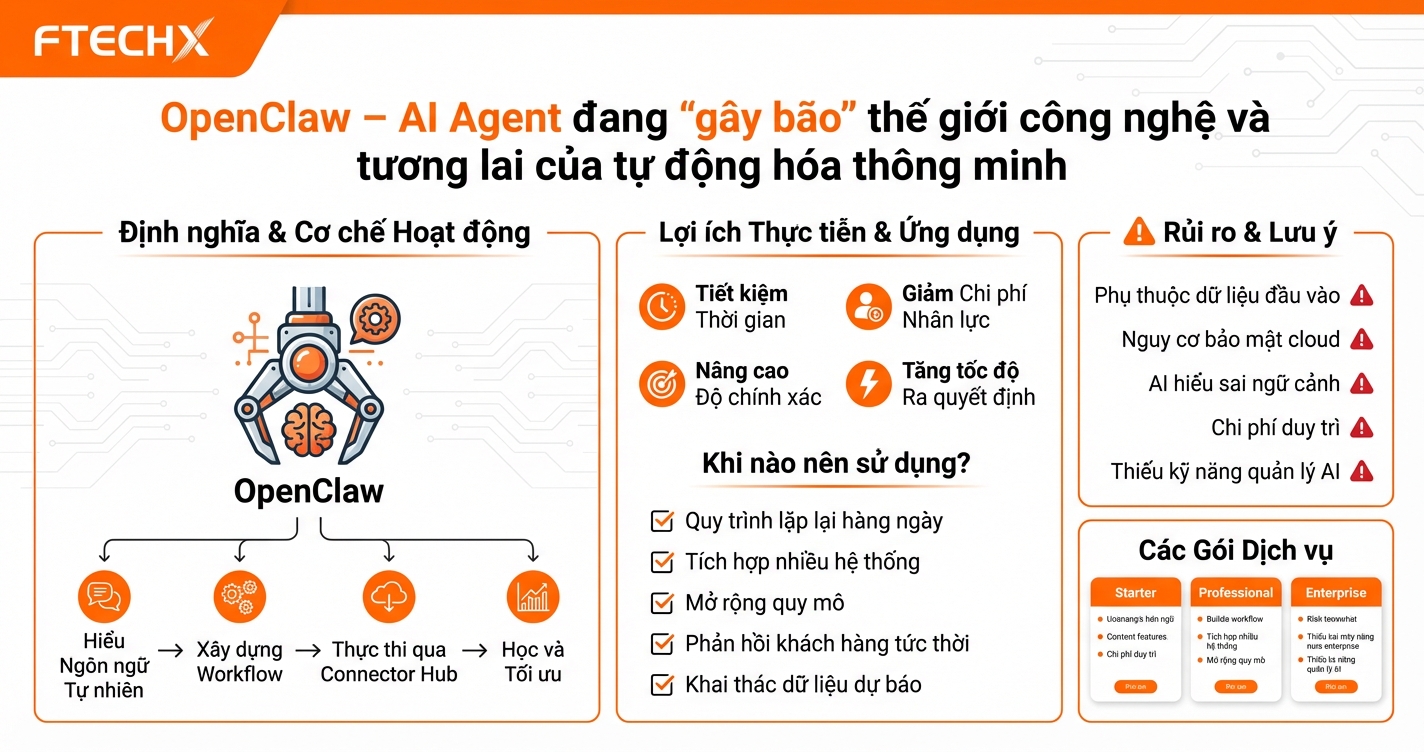
RAG (Retrieval-Augmented Generation) Là Gì?
Bạn có bao giờ hỏi ChatGPT một câu về dữ liệu nội bộ của công ty và nhận được câu trả lời "Tôi không có thông tin về điều đó"? Đó chính là lúc bạn cần RAG (Retrieval-Augmented Generation) — một kỹ thuật AI đang làm mưa làm gió trong giới công nghệ năm 2026.
RAG là gì?
RAG viết tắt của Retrieval-Augmented Generation (Sinh nội dung có truy xuất thông tin), là một kiến trúc AI kết hợp giữa tìm kiếm thông tin (Retrieval) và sinh văn bản (Generation). Thay vì chỉ dựa vào kiến thức có sẵn trong mô hình ngôn ngữ (LLM), RAG cho phép AI truy xuất dữ liệu từ bên ngoài (database, document, API) trước khi trả lời.
Nói đơn giản: RAG giống như việc bạn tra sách giáo khoa trước khi trả lời câu hỏi, thay vì trả lời từ trí nhớ.
Vì sao RAG quan trọng?
LLM truyền thống có 3 vấn đề lớn:
- Kiến thức cũ: Chỉ biết dữ liệu đến thời điểm huấn luyện
- Ảo giác (Hallucination): Dễ "bịa" thông tin khi không biết
- Không biết dữ liệu riêng: Không truy cập được tài liệu nội bộ
RAG giải quyết cả 3 vấn đề này bằng cách kết nối LLM với nguồn dữ liệu đáng tin cậy theo thời gian thực.
Cách RAG hoạt động
Quy trình RAG gồm 3 bước chính:
| Bước | Mô tả | Ví dụ |
|---|---|---|
| 1. Ingestion | Tài liệu được chia nhỏ (chunking) → chuyển thành vector → lưu vào Vector Database | PDF báo cáo tài chính → 500 chunks → lưu vào Pinecone |
| 2. Retrieval | Khi có câu hỏi, chuyển thành vector → tìm kiếm chunks tương tự nhất | "Doanh thu Q3?" → tìm chunks liên quan tài chính |
| 3. Generation | Gửi câu hỏi + chunks tìm được cho LLM → sinh câu trả lời | LLM đọc chunks → trả lời chính xác |
Công nghệ đằng sau RAG
Để xây dựng một hệ thống RAG hoàn chỉnh, bạn cần:
- Vector Database: Pinecone, Weaviate, Qdrant, hay ChromaDB (local)
- Embedding Model: Chuyển text thành vector — dùng OpenAI embeddings, Google Gecko, hay các model open-source
- LLM: GPT-4, Gemini, Claude, hay Llama 3 để sinh câu trả lời
- Orchestrator: LangChain, LlamaIndex, hay Haystack để kết nối các thành phần
RAG vs Fine-tuning
Nhiều người nhầm lẫn RAG với Fine-tuning. Dưới đây là so sánh nhanh:
| Tiêu chí | RAG | Fine-tuning |
|---|---|---|
| Dữ liệu thay đổi | Không cần retrain | Phải fine-tune lại |
| Kiểm soát nguồn | Cao (trích dẫn được nguồn) | Thấp (học ngầm) |
| Chi phí vận hành | Thấp hơn | Cao hơn (cần GPU) |
| Độ chính xác | Cao với dữ liệu cụ thể | Tốt với style/tone |
Ứng dụng thực tế của RAG
- Chatbot doanh nghiệp: Hỗ trợ khách hàng dựa trên tài liệu nội bộ
- Trợ lý pháp lý: Tra cứu luật, điều khoản hợp đồng
- Y tế: Tra cứu hồ sơ bệnh án, phác đồ điều trị
- Giáo dục: Hệ thống hỏi đáp dựa trên giáo trình
- Dev Support: Chatbot trả lời dựa trên documentation của dự án
Kết luận
RAG đang trở thành tiêu chuẩn mới trong xây dựng ứng dụng AI doanh nghiệp. Nó giải quyết bài toán lớn nhất của LLM: thiếu kiến thức chuyên ngành và dữ liệu thời gian thực.
Nếu bạn đang xây dựng một sản phẩm AI cần trả lời dựa trên dữ liệu cụ thể của mình, RAG chính là giải pháp bạn nên bắt đầu. Chi phí thấp, triển khai nhanh, và quan trọng nhất — có thể trích dẫn nguồn gốc thông tin.
💡 Mẹo nhỏ: Bắt đầu với LangChain + ChromaDB (local, free) + Gemini API (miễn phí) để xây dựng RAG pipeline đầu tiên trong vòng 30 phút.
Bạn đã thử xây dựng ứng dụng RAG chưa? Chia sẻ trải nghiệm của bạn ở phần bình luận nhé!
![GEO là gì? Từ A-Z về Generative Engine Optimization [2025]](upload/image/post/y-nghia-cua-geo-trong-marketing-va-kinh-doanh.webp)

![Elementor là gì? Từ A-Z Về Trình Tạo Trang Kéo Thả Số 1 WordPress [2025]](upload/image/post/elementor.webp)